CS 공부 -Spring
Spring Framework란
스프링 프레임워크는 자바 개발을 편리하게 해주는 오프소스 프레임워크를 말한다.
- 경량 컨테이너로서 자바 객체를 직접 관리한다
- 각각의 객체 생성, 소멸과 같은 라이프 사이클을 관리하며 스프링으로부터 필요한 객체를 얻어 올수 있다.
- IoC ( Inverson of Contorl 제어의 역전 )을 통해 어플리케이션의 느슨한 결합을 도모
- 컨트롤의 제어권이 사용자가 아닌 프레임워크에 있어서 필요에 따라 스프링에서 사용자의 코드를 호출함
- IOC 컨테이너는 DI를 통해 주입시키는데 주입하는 방법은 생성자,메소드의 setter, 멤버변수에 @Inject,@Autowired 를 통해 주입합니다.
- DI ( Dependency Injection 의존성 주입 )을 지원
- 각각의 계층이나 서비스들 간에 의존성이 존재할 경우 프레임워크가 서로 연결시켜준다.
- AOP ( Aspect-Oriented Programing ) 을 지원
- 트랜잭션이나 로깅,보안과 같이 여러 모듈에서 공통적으로 사용하는 기능의 경우 해당 기능들을 분리하여 관리할 수 있다.
Spring 스코프
Bean 스코프란
스코프는 빈이 존재할 수 있는 범위를 뜻한다. 스프링에서는 다양한 스코프를 지원한다.
- 싱글톤
- 기본 스코프, 스프링 컨테이너의 시작과 종료까지 유지되는 가장 넓은 범위의 스코프
- 싱글톤 스코프의 빈을 요청하면 모두 동일한 스프링 빈을 반환한다.
- 프로토타입
- 프로토타입 빈의 생성과 의존관계 주입 까지만 스프링 컨테이너가 관여하고 그 이후로는 관여하지 않는 매우 짧은 범위의 스코프이다.
- 조회하는 빈이 프로로타입 스코프에 있다면 스프링 컨테이너는 항상 새로운 인스턴스를 생성해서 반환.
- 웹 관련 스코프
- request: 웹 요청이 들어오고 나갈때까지 유지되는 스코프
- session : 웹 세션이 생성되고 종료될때까지 유지되는 스코프
- application 웹의 서블릿 컨텍스트와 같은 범위로 유지되는 스코프
프로토타입 특징 정리
- 싱글톤은 스프링 컨테이노와 생명주기를 같이하지만, 프로토타입 스프링 빈은 생명 주기를 달리한다.
- 싱글톤 스프링 빈은 매번 스프링 컨테이너에서 동일한 인스턴스를 반환하지만, 프로토타입 스프링 빈은 스프링 컨테이너에 요청할 때마다 새로운 스프링 빈을 생성 후 의존관계까지 주입및 초기화 진행후 반환한다.
- 프로토타입 스프링 빈은 소멸 메서드가 호출되지 않는다.
- 클라이언트가 프로토타입 스프링 빈은 직접 관리해야한다. ( 소멸 메소드도 직접 호출해야 한다 .( destroy() )
@Transactional
@Transactional을 메소드 또는 클래스에 명시하면, AOP를 통해 Target이 상속하고 있는 인터페이스 또는 Target 객체를 상속한 Proxy 객체가 생성되며, Proxy 객체의 메소드를 호출하면 Target 메소드 전 후로 트랜잭션 처리를 수행합니다.
의존성(Dependency)이란
의존성 이란??
객체의 세계에서 협력은 필수적이며, 객체가 협력한다는 것은 객체 간의 의존성이 존재한다는 것이다. 여기서 의존성이란 파라미터나 리턴값 또는 지역변수 등으로 다른 객체를 참조하는 것을 의미한다.
의존성은 객체 간의 협력을 위해 필수적이다. 하지만 의존성은 위험하므로 의존성은 최소화되어야 한다. 왜냐하면 한 객체가 다른 객체에 의존한다는 것은 다른 객체가 변할 때 변경이 전파될 수 있다는 것을 의미하기 때문인데, 이를 의존성 전이라고 한다.
이러한 것들은 불필요한 변경이므로 개방 폐쇠 원칙을 준수하도록 의존성 전이를 최소화해야 한다. 의존성 전이를 최소화하기 위해서는 컴파일 타임 의존성이 아닌 런타임 의존성을 가져야 하는데, 두 의존성이 무엇이고 왜 런타임 의존성을 가져야 하는지 살펴보도록 하자.
컴파일타임 의존성
컴파일타임 의존성이란 코드를 컴파일하는 시점에 결정되는 의존성이며, 클래스 사이의 의존성에 해당한다. 일반적으로 추상화된 클래스나 인터페이스가 아닌 구체 클래스에 의존하면 컴파일타임 의존성을 갖게된다.
런타임 의존성
런타임 의존성이란 코드(애플리케이션)를 실행하는 시점에 결정되는 의존성이며, 객체 사이의 의존성에 해당한다. 일반적으로 추상화된 클래스나 인터페이스에 의존할 때 런타임 의존성을 갖게 되며, 이러한 이유로 런타임 의존성과 컴파일 의존성은 다를 수 있다.
IoC 제어의 역전
Inversion Of Control - 제어의 역전
- 의존성은 쉽게 말해 어떤 객체가 사용해야 할 객체라고 할 수 있고, 이것을 직접 new 생성자 등을 사용하여 만들어 쓰면 의존성을 자기가 직접 만들어 쓴다고 할 수 있다.
- 밖에서 나에게 의존성을 주입해주는 것을 DI라고 합니다. 따라서 DI는 IoC의 일종이라고 생각하면 된다.
- 객체의 의존성을 역전시켜 객체 간의 결합도를 줄이고 유연한 코드를 작성할 수 있게 하여 가독성 및 코드 중복, 유지 보수를 편하게 할 수 있게 한다.
- 스프링이 모든 의존성 객체를 스프링이 실행될때 다 만들어주고 필요한곳에 주입시켜줌으로써 Bean들은 싱글턴 패턴의 특징을 가지며,제어의 흐름을 사용자가 컨트롤 하는 것이 아니라 스프링에게 맡겨 작업을 처리하게 된다.
- 스프링에서의 의존성 주입은 반드시 Bean으로 등록된 객체들 끼리만 가능합니다. 스프링 IoC 컨테이너는 Bean으로 등록되지 않은 객체에는 의존성 주입을 해 주지 않습니다.
Bean과 스프링 IoC 컨테이너
스프링 IoC 컨테이너가 관리하는 객체들을 Bean 이라고 부릅니다. 스프링은 이러한 Bean들의 의존성을 관리하고, 객체를 만들어 주며, Bean으로 등록을 해 주고, 이렇게 만들어진 것들을 관리합니다.
스프링 IoC컨테이너는 2가지 종류가 존재.
- ApplicationContext 혹은 BeanFactory
- Bean Factory
- DI의 기본사항을 제공하는 컨테이너,Bean을 생성하고 분배하는 작업을 한다.
- 처음 getBean()이 호출된 시점에서야 해당 빈을 생성한다.(Lazy Loading)
- ApplicationContext
- Bean팩토리와 유사하지만 더 많은 기능을 제공한다. 미리 빈을 생성해 놓아 (싱글톤) 빈이 필요할 때 즉시 사용 할 수 있도록 보장한다.
- ApplicationContext는 BeanFactory를 상속받으므로 둘 다 같은 일을 하는 것임
- Bean Factory
Bean을 등록하는 방법 , Component , Configuration 차이
- @Component 어노테이션을 사용하는 것.
- @Controller,@Service,@Repository는 모두 @Component를 내장하고 있다.
- 설정 클래스를 따로 만들어 @Configuration 어노테이션을 붙이고, 해당 클래스 안에서 빈으로 등록할 메소드를 만들어 @Bean 어노테이션을 붙여주면 자동으로 해당 타입의 빈 객체가 생성
- @ComponentScan 어노테이션은 어느 지점부터 컴포넌트를 찾으라고 알려주는 역할을 하고 @Component는 실제로 찾아서 빈으로 등록할 클래스를 의미한다.
- Spring IoC 컨테이너가 IoC 컨테이너를 만들고 그 안에 빈을 등록할때 사용하는 인터페이스들을 라이프 사이클 콜백이라고 부른다.
- 라이프 사이클 콜백 중에는 @Component 어노테이션을 찾아서 이 애노테이션이 붙어있는 모든 클래스의 인스턴스를 생성해 빈으로 등록하는 작업을 수행하는 어노테이션 프로세서가 등록돼있다.
- @ComponentScan 어노테이션은 어디서부터 컴포넌트를 찾아볼 것인지 알려주는 역할을 한다.
- @ComponentScan이 붙어있는 클래스가 있는 패키지에서부터 모든 하위 패키지의 모든 클래스를 훑어보며 @Component 애노테이션(또는 @Component 애노테이션을 사용하는 다른 어노테이션)이 붙은 클래스를 찾는다.
- Spring이 IoC 컨테이너를 만들때 위와 같은 과정을 거쳐 빈으로 등록해주는 것이다.
@Bean
- 개발자가 직접 제어가 불가능한 외부 라이브러리를 사용할 때 사용한다.
- @Configuraion을 선언한 class내부에서 사용한다.
- 메서드 단위로 지정할 수 있다. (그렇지 않을 시 컴파일 에러를 발생시킨다.)
- 즉, 개발자가 작성한 메서드를 통해 반환되는 객체를 Bean으로 만든다.
@Component
- 개발자가 직접 작성한 class를 Bean으로 등록 할 수 있게 만들어 준다.
- class 단위로 지정할 수 있다. (그렇지 않을 시 컴파일 에러를 발생시킨다.)
- @Controller, @Service, @Repository... 내부에 @Component가 정의되어 있다.
- 즉, 개발자가 작성한 class를 Bean으로 만든다.
@Configuration
- 스프링이 Bean 팩토리를 위한 오브젝트 설정을 담당하는 class라고인식하게 해준다.
- 1개 이상의 @Bean을 제공하는 class의경우 @Configuraton을 명시해야 된다.
- @Configuration 내부에 @Component가 정의되어 있으므로 별개의 개념으로 보면 안 된다.
정리
쉽게 생각하면 개발자가 직접 컨트롤이 안되는 라이브러리에 class들을 Bean으로 지정하고 싶을 때는
메서드에 @Bean + @Configuration 어노테이션을 사용하고, 개발자가 직접 만든 class를 Bean으로 지정하고 싶을 때는
class에 @Component 어노테이션을 사용하면 된다.
서블릿 이란
클라이언트의 요청을 처리하고, 그 결과를 반환하는 Servlet 클래스의 구현 규칙을 지킨 자바 웹 프로그래밍 기술
Spring MVC에서 Controller로 이용되며, 사용자의 요청을 받아 처리한 후에 결과를 반환한다.
서블릿의 동작 방식
- 클라이언트가 URL을 입력하면 HTTP Request가 Servlet Container로 전송됩니다.
- 요청받은 Servlet Container는 HttpServletReqeust,HttpServletResponse객체를 생성합니다.
- web.xml을 기반으로 사용자가 요청한 URL이 어느 서블릿에 대한 요청인지 찾습니다.
- 해당 서블릿에서 service 메소드를 호출한 후 GET,POST여부에 따라 doGet()또는 doPost()를 호출합니다.
- doGet() or doPost() 메소드는 동적 페이지를 생성한 후 , HttpSerlvetResponse객체에 응답을보냅니다.
- 응답이 끝나면 HttpServletRequest,HttpServletResponse객체를 소멸 시킵니다.
Servlet 특징
- 클라이언트의 요청에 대해 동적으로 작동하는 웹 어플리케이션 컴포넌트
- html을 사용하여 요청에 응답한다.
- Java Thread를 이용하여 동작한다.
- MVC 패턴에서 Controller로 이용된다.
- HTTP 프로토콜 서비스를 지원하는 javax.servlet.http.HttpServlet 클래스를 상속받는다.
- UDP보다 처리 속도가 느리다.
- HTML 변경 시 Servlet을 재컴파일해야 하는 단점이 있다.
서블릿의 생명 주기
- 클라이언트의 요청이 들어오면 컨테이너는 해당 서블릿이 메모리에 있는지 확인하고, 없을 경우 init()메소드를 호출하여 적재합니다. init()메소드는 처음 한번만 실행되기 때문에, 서블릿의 쓰레드에서 공통적으로 사용해야하는 것이 있다면 오버라이딩하여 구현하면 됩니다. 실행 중 서블릿이 변경될 경우, 기존 서블릿을 파괴하고 init()을 통해 새로운 내용을 다시 메모리에 적재합니다.
- init()이 호출된 후 클라이언트의 요청에 따라서 service()메소드를 통해 요청에 대한 응답이 doGet()가 doPost()로 분기됩니다. 이때 서블릿 컨테이너가 클라이언트의 요청이 오면 가장 먼저 처리하는 과정으로 생성된 HttpServletRequest, HttpServletResponse에 의해 request와 response객체가 제공됩니다.
- 컨테이너가 서블릿에 종료 요청을 하면 destroy()메소드가 호출되는데 마찬가지로 한번만 실행되며, 종료시에 처리해야하는 작업들은 destroy()메소드를 오버라이딩하여 구현하면 됩니다.
Servlet Container ( 서블릿 컨테이너 )
- 서블릿을 관리해주는 컨테이너,
- 클라이언트의 요청 (Request)을 받아주고 응답(Response)할 수 있게, 웹 서버와 소켓으로 통신하며 대표적으로 톰캣이 있습니다. 톰캣은 실제로 웹 서버와 통신하여 JSP (자바 서버 페이지)와 Serlvet이 작동하는 환경을 제공
Servlet Container 역할
- 웹서버와의 통신 지원
- 서블릿 컨테이너는 서블릿과 웹서버가 손쉽게 통신할 수 있게 해줍니다. 일반적으로 우리는 소켓을 만들고 listen,
- accept 등을 해야하지만 서블릿 컨테이너는 이러한 기능을 API로 제공하여 복잡한 과정을 생략할 수 있게 해줍니다.
- 그래서 개발자가 서블릿에 구현해야 할 비지니스 로직에 대해서만 초점을 두게끔 도와줍니다.
- 서블릿 생명주기(Life Cycle) 관리
- 서블릿 컨테이너는 서블릿의 탄생과 죽음을 관리합니다. 서블릿 클래스를 로딩하여 인스턴스화하고,
- 초기화 메소드를 호출하고, 요청이 들어오면 적절한 서블릿 메소드를 호출합니다.
- 또한 서블릿이 생명을 다 한 순간에는 적절하게 Garbage Collection(가비지 컬렉션)을 진행하여 편의를 제공합니다.
- 멀티쓰레드 지원 및 관리
- 서블릿 컨테이너는 요청이 올 때 마다 새로운 자바 쓰레드를 하나 생성하는데, HTTP 서비스 메소드를
- 실행하고 나면, 쓰레드는 자동으로 죽게됩니다. 원래는 쓰레드를 관리해야 하지만 서버가 다중 쓰레드를
- 생성 및 운영해주니 쓰레드의 안정성에 대해서 걱정하지 않아도 됩니다.
- 선언적인 보안 관리
- 서블릿 컨테이너를 사용하면 개발자는 보안에 관련된 내용을 서블릿 또는 자바 클래스에 구현해 놓지 않아도 됩니다.
- 일반적으로 보안관리는 XML 배포 서술자에 다가 기록하므로, 보안에 대해 수정할 일이 생겨도 자바 소스 코드를
- 수정하여 다시 컴파일 하지 않아도 보안관리가 가능합니다.
PSA (Portable Service Abstraction)
- PSA란 환경의 변화와 관계없이 일관된 방식의 기술로의 접근 환경을 제공하는 추상화 구조를 말한다.
- 이는 POJO원칙을 철저히 따른 Spring의 기능으로, Spring에서 동작할 수 있는 Library들은 POJO 원칙을 지키게끔 PSA형태의 추상화가 되어있음을 의미한다.
- PSA가 적용된 코드라면 나의 코드가 바뀌지 않고, 다른 기술로 간편하게 바꿀 수 있도록 확장성이 좋고, 기술에 특화되어 었지 않는 코드를 의미한다
- Spring은 Spring Web MVC, Spring Trasaction, Spring Cache등의 다양한 PSA를 제공한다.
POJO ( Plain Old Java Object )
- POJO란 Plain Old Java Object의 약자로 다른 클래스나 인터페이스를 상속/implements 받아 메서드가 추가된 클래스가 아닌 일반적으로 우리가 잘 알고 있는 getter,setter 같이 기본적은 기능만 가진 자바 객체를 말한다.
- 객체지향적인 원리에 충실하면서 환경과 기술에 종속되지 않고, 필요에 따라 재활용될 수 있는 방식으로 설계된 오브젝트를 말한다. 그러한 POJO에 애플리케이션의 핵심로직과 기능을 담아 설계하고 개발하는 방법을 POJO 프로그래밍이라고 할 수 있다.
POJO의 조건
- 특정 규약에 종속되지 않는다.
- 자바 언어와 꼭 필요한 API외에는 종속되지 말아야 한다. EJB2와 같이 특정 규약을 따라 만들게 하는 경우는 대부분 규약에서 제시하는 특정 클래스를 상속하도록 요구한다. 그럴 경우 자바 단일 상속 제한 때문에 더 이상 해당 클래스에 객체지향적인 설계를 적용하기 어려워 지는 문제가 발생한다.
- 특정 환경에 종속되지 않는다.
- 특정 기업의 프레임워크나 서버에서만 동작가능한 코드라면 POJO라 할 수 없다.
- POJO는 환경에 독립적이어야 한다.
- 객체 지향적 원리에 충실해야 한다.
POJO의 장점
- 깔끔한 코드 , 간편한 테스트
- 객체지향적인 설계를 자유롭게 적용
- 객체지향 프로그램은 엔터프라이즈 시스템에서와 같이 복잡합 도메인을 가진 곳에서 가장 효과적으로 사용 할 수있다.
AOP 관점 지향 프로그래밍
- AOP는 Aspect Oriented Programming의 약자로 관점 지향 프로그래밍이라고 불린다. 관점 지향은 쉽게 말해 어떤 로직을 기준으로 핵심적인 관점, 부가적인 관점으로 나누어서 보고 그 관점을 기준으로 각각 모듈화하겠다는 것이다.
- 예로들어 핵심적인 관점은 결국 우리가 적용하고자 하는 핵심 비즈니스 로직이 된다. 또한 부가적인 관점은 핵심 로직을 실행하기 위해서 행해지는 데이터베이스 연결, 로깅, 파일 입출력 등을 예로 들 수 있다.
- AOP에서 각 관점을 기준으로 로직을 모듈화한다는 것은 코드들을 부분적으로 나누어서 모듈화하겠다는 의미다. 이때, 소스 코드상에서 다른 부분에 계속 반복해서 쓰는 코드들을 발견할 수 있는 데 이것을 흩어진 관심사 (Crosscutting Concerns)라 부른다.
- 흩어진 관심사를 Aspect로 모듈화하고 핵심적인 비즈니스 로직에서 분리하여 재사용하겠다는 것이 AOP의 취지
DI 의존성 주입
- 객체를 직접 생성하는 게 아니라 외부에서 생성한 후 주입 시켜주는 방식이다.
- DI(의존성 주입)를 통해서 모듈 간의 결합도가 낮아지고 유연성이 높아지며 코드의 재사용성을 높일 수 있다.
- 의존성 주입은 생성자 주입 , 필드 주입, Setter 주입의 3가지 방법이 존재한다.
- 생성자 주입
- 순환 참조를 방지할 수 있다.
- 필드 주입과 Setter주입은 빈이 생성 된 후에 참조를 하기 때문에 어플리케이션이 아무 오류 없이 작동되지만 실제 코드가 호출되면 에러가 발생한다. 하지만 생성자 주입 방식은 실행하면 BeanCurrentLyInCreationException이 발생한다.
- 순환 참조뿐만 아니라 더 나아가서 의존 관계에 내용을 외부로 노출 시킴으로써 애플리케이션을 실행하는 시점에서 오류를 체크 할 수 있다.
- 불변성
- 생성자로 의존성을 주입 할 때 final로 선언하여 이로인해 런타임에서 의존성을 주입받는 객체가 변할 일이 없어지게 된다.
- 하지만 수정자 주입이나 일반 메서드 주입을 이용하면 불필요하게 수정의 가능성을 열어두게 되고 이는 OOP의 5가지 원칙중 OCP (개방 - 폐쇄의 원칙)을 위반한다.
- 그러므로 생성자 주입을 통해 변경의 가능성을 배제하고 불변성을 보장하는것이 좋다.
- 또한 필드 주입 방식은 null의 가능성이 있는데 final로 선언한 생성자는 null이 불가능하다.
- 테스트에 용이하다
- 독립적으로 인스턴스화가 가능한 POJO(Plain Old Java Object)를 사용하면 ,DI 컨테이너 없이도 의존성을 주입하여 사용 할 수있다. 이를 통해 코드 가독성이 높아지며 유지보수가 용이하고 테스트의 격리성과 예측 가능성을 높일 수 있다는 점이 생긴다. 위와 같은 이유로 필드 주입이나 수정자 주입보다는 생성자 주입의 사용을 권장한다.
- 순환 참조를 방지할 수 있다.
- 필드 주입
- 필드에 @Autowired 어노테이션만 붙여주면 자동으로 의존성 주입이 완료된다.
- 사용법이 매우 간단하기 때문에 가장 많이 접할 수 있는 방법중 하나다.
- 단점
- 코드가 간결하지만, 외부에서 변경하기 힘들다.
- 프레임워크에 의존적이고 객체지향적으로 좋지 않다.
- 수정자 주입(Setter)
- Setter메소드에 @Autowired 어노테이션을 붙이는 방법
- 단점
- 수정자 주입을 사용하면 setXXX메서드를 public으로 열어두여야 하기 때문에 언제 어디서든 변경이 가능하기 때문에 좋지 않다.
- 생성자 주입
스케일 업 , 스케일 아웃
스케일 업
- 스케일 업은 기존 서버의 사양을 업그레이드해 시스템을 확장하는 것을 말한다.
- CPU나 RAM등을 추가하거나, 고성능의 부품, 서버로 교환하는 방법이다.
- 하나의 서버의 사양을 업그레이드 하기 때문에 수직 스케일로 불리기도 한다.
스케일 아웃
- 스케일 아웃은 서버를 여러 대 추가하여 시스템을 확장하는 것을 말한다.
- 서버가 여러 대로 나뉘기 때문에 각 서버에 걸리는 부하를 균등하게 해주는 ' 로드밸런싱 ' 이 필수적으로 동반되야 함
- 여러 대의 서버로 나눠 시스템을 확장하기 때문에 수평 스케일로 불리기도 한다.
스프링 Bean 라이프 사이클
- 스프링 IoC 컨테이너 생성
- 스프링 빈 생성
- 의존관계 주입
- 초기화 콜백 메소드를 호출
- 사용
- 소멸 전 콜백 메소드 호출
- 스프링 종료
빈 생명주기 콜백 3가지
- 인터페이스 ( InitializingBean,DisposableBean )
- InitializingBean은 afterPropertiesSet()메소드로 초기화를 지원한다. (의존관계 주입이 끝난 후에 초기화 )
- DisposableBean은 destroy() 메소드로 소멸을 지원한다. (Bean 종료 전에 마무리작업,예를 들면 자원 해제 (clsoe()등 ))
- 단점
- InitalizingBean, DisposableBean 인터페이스는 스프링 전용 인터페이스이다. 해당 코드가 인터페이스에 의존한다.
- 초기화, 소멸 메소드를 오버라이드 하기 때문에 메소드명을 변경할 수 없다.
- 코드를 커스터마이징 할 수 없는 외부 라이브러리에 적용 불가능하다.
- 설정 정보에 초기화 메소드 ,종료 메소드 지정
- 장점
- 메소드 명을 자유롭게 부여 가능하다.
- 스프링 코드에 의존하지 않는다.
- 설정 정보를 사용하기 때문에 코드를 커스터마이징 할 수 없는 외부라이브러리도 적용 가능하다.
- 단점
- Bean 지정시 initMethod와 destroyMEthod를 직접 지정해야 하기에 번거롭다.
- 장점
- @PostConstruct,@PreDestroy 어노테이션 지원
- 장점
- 최신 스프링에서 가장 권장하는 방법이다.
- 어노테이션 하나만 붙이면 되므로 매우 편리하다.
- 패키지가 javax.anotation.xxx이다. 스프링에 종속적인 기술이 아닌 JSR-250이라는 자바 표준이다. 따라서 스프링이 아닌 다른 컨테이너에서도 동작한다.
- 컴포넌트 스캔과 잘 어울린다.
- 단점
- 커스터마이징이 불가능한 외부 라이브러리에서 적용이 불가능하다
- 외부 라이브러리에서 초기화,종료를 해야 할 경우 두번째방법 , @Bean의 initMetho와 destroyMethod를 사용하자.
- 커스터마이징이 불가능한 외부 라이브러리에서 적용이 불가능하다
- 장점
AOP Interceptor Filter 차이
Filter
- 요청과 응답을 거른뒤 정제하는 역할을 한다.
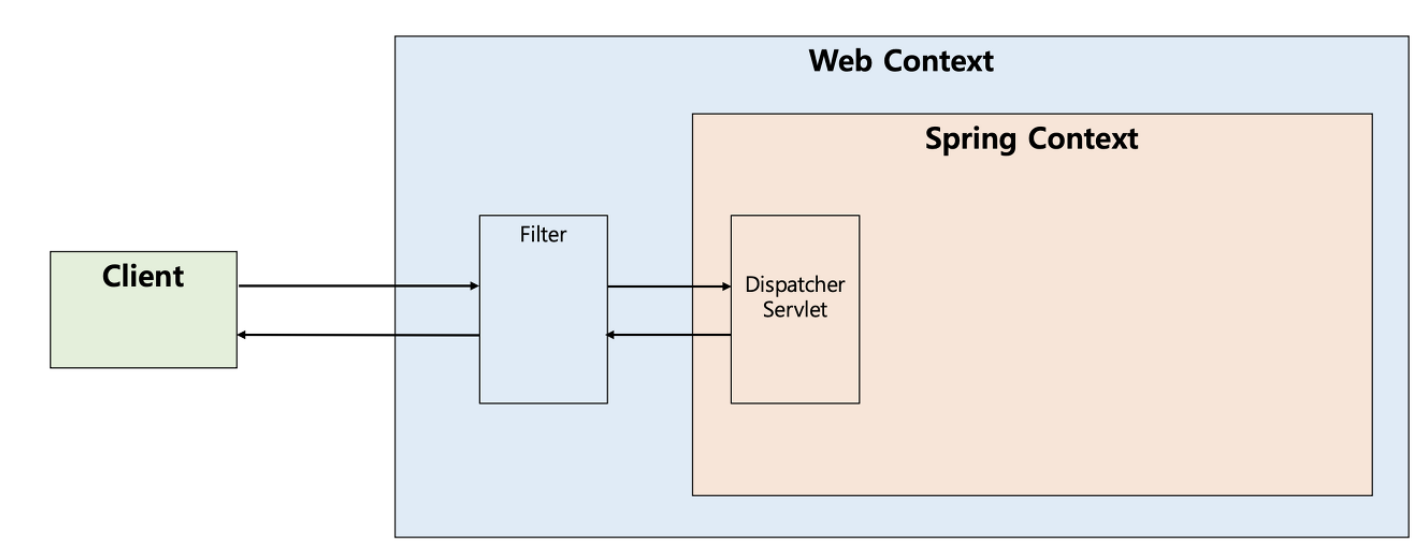
- Dispatcher Servlet 전/후 ServletRequest / ServletResponse 객체 변경 및 조작 수행 가능
- WAS 구동 시 FilterMap이라는 배열에 등록되고 , 실행 시 Filter Chain을 구성하여 순차적으로 실행
- Spring Context 외부에 존재하여 스프링과 무관하게 전역적으로 처리해야하는 작업들을 처리할때 사용.
- 일반적으로 web.xml에 설정
- 예외 발생 시 Web Application에서 예외 처리
- 공통된 보안 및 인증/인가 관련 작업 (XSS 방어)를 하여 올바른 요청이 아닐 경우 차단을 할 수 있다 스프링 컨테이너까지 요청이 전달되지 못하고 차단되므로 안정성을 더욱 높일 수 있다
- 이미지/데이터 압축 및 문자열 인코딩 변환 처리
- Spring과 분리되어야 하는 기능
- 모든 요청에 대한 로깅등 웹 애플리케이션에 전반적으로 사용되는 기능을 구현하기에 적당하다.
- Filter는 다음 체인으로 넘기는 ServletRequest/ServletResponse 객체를 조작할 수 있다는 점에서 Interceptor보다 훨씬 강력한 기술이다.
Filter의 메서드
필터를 추가하기 위해서는 javax.servlet의 Filter 인터페이스를 구현(implements)해야 하며 이는 다음의 3가지 메서드를 가지고 있다
- init() : 필터 인스턴스 초기화
- 필터 객체를 초기화하고 서비스에 추가하기 위한 메서드이다. 웹 컨테이너가 1회 init 메서드를 호출하여 필터 객체를 초기화하면 이후의 요청들은 doFilter를 통해 처리된다.
- doFilter() : 실제 전/후 로직 처리
- url-pattern에 맞는 모든 HTTP 요청이 디스패처 서블릿으로 전달되기 전에 웹 컨테이너에 의해 실행되는 메서드.
- doFilter의 파라미터로는 FilterChain이 있는데, FilterChain의 doFilter를 통해 다음 대상으로 요청을 전달하게 된다
- chain.doFilter() 전/후에 우리가 필요한 처리 과정을 넣어줌으로써 원하는 처리를 진행 할 수 있다.
- destroy() : 필터 인스턴스 종료
- 필터 객체를 서비스에서 제거하고, 사용하는 자원을 반환하기 위한 메서드이다. 이는 웹 컨테이너에 의해 1번 호출되며 이후에는 이제 doFilter에 의해 처리되지 않는다.
Interceptor
- Dispatcher Servlet 이후 Controller 호출 전/후에 끼어들어 기능 수행
- Spring Context 내부에서 Controller의 요청과 응답에 관여하며 모든 Bean에 접근 가능.인터셉터에서는 클라이언트의 요청과 관련되어 전역적으로 처리해야 하는 작업들을 처리할 수 있다
- 일반적으로 servlet-context.xml에 설정
- 예외 발생 시 @ControollerAdvie에서 @ExceptionHandler를 사용해 예외처리
- 세부적인 보안 및 인증/인가 공통 작업 ( 특정 사용자는 특정 기능을 사용하지 못하게 막는 등 )
- API 호출에 대한 로깅
- Controller로 넘겨주는 정보( 데이터 )의 가공
- 필터와 다르게 HttpServletRequest나 HttpServletResponse 등과 같은 객체를 제공받으므로 객체 자체를 조작 할 수는 없음.대신 해당 객체가 내부적으로 갖는 값은 조작할 수 있으므로 컨트롤러로 넘겨주기 위한 정보를 가공하기에 용이하다.
- EX) JWT 토큰 정보를 파싱 해서 컨트롤러에게 사용자의 정보를 제공하도록 가공할 수 있는 것이다. 그 외에도 우리는 다양한 목적으로 API 호출에 대한 정보들을 기록해야 할 수 있다.
- 이러한 경우에 HttpServletRequest나 HttpServletResponse를 제공해주는 인터셉터는 클라이언트의 IP나 요청 정보들을 포함해 기록하기에 용이하다.
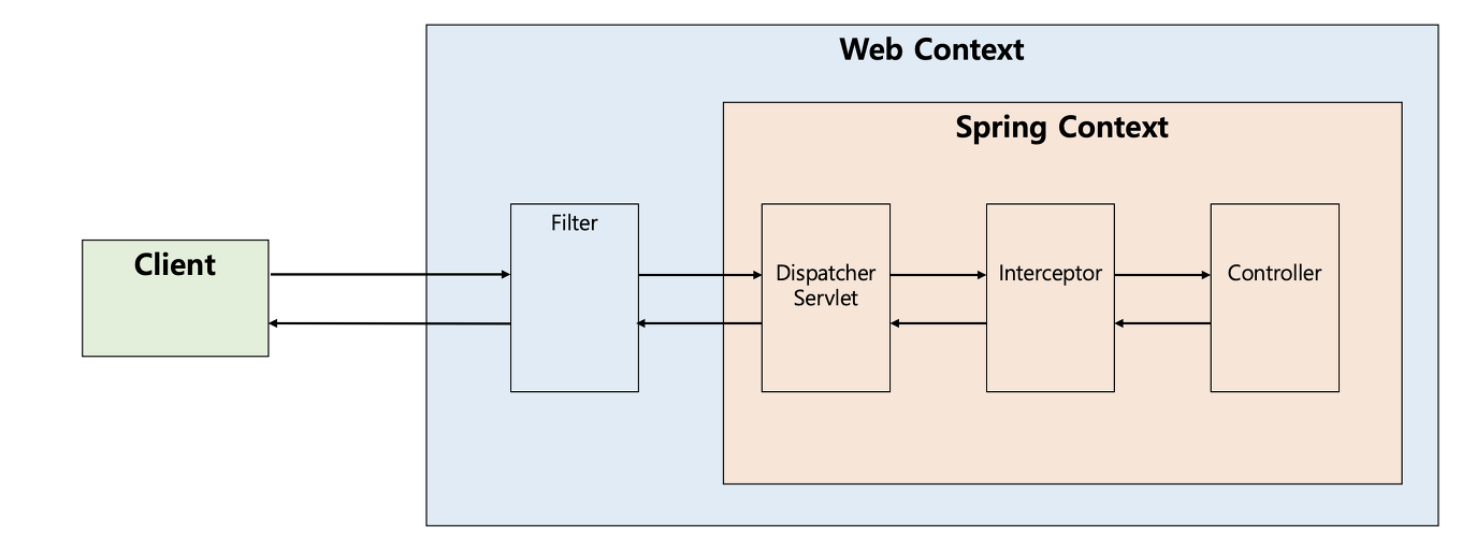
스프링의 모든 빈 객체에 접근 할 수 있다. 인터셉터는 여러 개를 사용 할 수 있고, 로그인 체크 ,권한 체크 ,프로그램 실행 시간 계산 작업 로그 확인등의 업무 처리에 사용된다.
Interceptor의 메서드
- preHandelr() : 컨트롤러 메서드가 실행되기 전
- 컨트롤러가 호출되기 전에 실행된다. 그렇기 때문에 컨트롤러 이전에 처리해야 하는 전처리 작업이나 요청 정보를 가공하거나 추가하는 경우에 사용 할 수 있다. preHandle의 3번째 파라미터인 handler파라미터는 핸들러 매핑이 찾아준 컨트롤러 빈에 매핑디는 HandlerMethod라는 새로운 타입의 객체로써, @RequestMapping이 붙은 메서드의 정보를 추상화한 객체이다. 또한 preHandle의 반환 타입은 boolean인데 반환값이 true이면 다음 단계로 진행이 되지만, false라면 작업을 중단하여 이후의 작업(다음 인터셉터 또는 컨트롤러)은 진행되지 않는다.
- postHanler(): 컨트롤러 메소드 실행 직후 view 페이지 렌더링 되기 전
- 컨트롤러를 호출된 후에 실행된다. 그렇기 때문에 컨트롤러 이후에 처리해야 하는 후처리 작업이 있을 때 사용할 수 있다. 이 메서드에는 컨트롤러가 반환하는 ModelAndView 타입의 정보가 제공되는데, 최근에는 Json 형태로 데이터를 제공하는 RestAPI 기반의 컨트롤러(@RestController)를 만들면서 자주 사용되지는 않는다.
- afterCompletion(): view 페이지가 렌더링 되고 난 후
- 모든 뷰에서 최종 결과를 생성하는 일을 포함해 모든 작업이 완료된 후에 실행된다. 요청 처리 중에 사용한 리소스를 반환할 때 사용하기에 적합하다.
# Filter와 Interceptor의 비교
- Filter는 WAS단에 설정되어 Spring과 무관한 자원에 대해 동작하고, Interceptor는 Spring Context 내부에 설정되어 컨트롤러 접근 전, 후에 가로채서 기능 동작
- Filter는 doFilter() 메소드만 있지만, Interceptor는 pre와 post로 명확하게 분리
- Interceptor의 경우 AOP 흉내 가능
- handlerMethod(@RequestMapping을 사용해 매핑 된 @Controller의 메소드)를 파라미터로 제공하여 메소드 시그니처 등 추가 정보를 파악해 로직 실행 여부 판단 가능
- 필터와 인터셉터는 각각 관리되는 컨테이너와 Request/Response의 조작 가능 여부가 다르고, 그에 따라 용도가 다르다.
- 필터는 Request와 Response를 조작할 수 있지만 인터셉터는 조작할 수 없다.
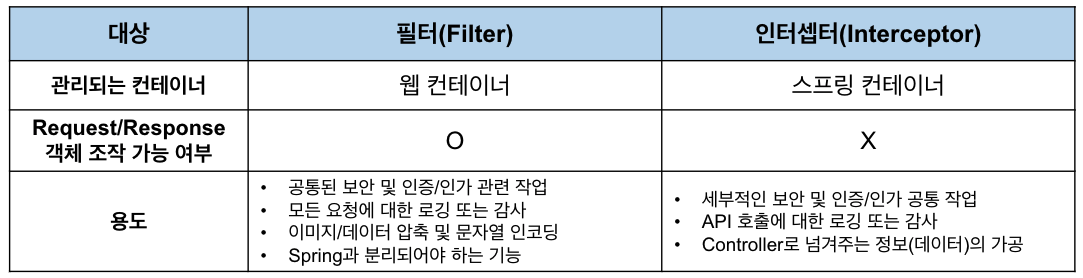
출처 : https://mangkyu.tistory.com/173
AOP
- AOP는 OOP를 보완하기 위해 나온 개념이다. 객체 지향의 프로그래밍을 했을 때 중복을 줄일 수 없는 부분을 줄이기 위해 종단면(관점)에서 바라보고 처리한다.
- 주로 '로깅', '트랜잭션','에러 처리'등 비즈니스단의 메서드에서 조금 더 세밀하게 조정하고 싶을 때 사용, Interceptor나 Filter와는 달리 메서드 전 후의 지점에 자유롭게 설정이 가능하다.
- Interceptor와 Filter는 주소(URL)로 대상을 구분해서 걸러내야하는 반면, AOP는 주소, 파라미터, 애노테이션 등 PointCut이 지원하는 다양한 방법으로 대상을 지정할 수 있다. 즉 URL 기반이 아닌 PointCut 단위로 동작한다.
AOP의 Advice와 HandlerInterceptor의 가장 큰 차이는 파라미터의 차이다. Advice의 경우 JoinPoint나 ProceedingJoinPoint 등을 활용해서 호출한다. 반면 HandlerInterceptor는 Filter와 유사하게 HttpServletRequest, HttpServletResponse를 파라미터로 사용한다.
AOP PointCut 어노테이션
- @Before: 대상 메서드의 수행 전
- @After: 대상 메소드의 수행 후
- @After-returning: 대상 메소드의 정상적인 수행 후
- @After-throwing: 예외발생 후
- @Around: 대상 메서드의 수행 전, 후
3개 각각의 차이점
1) 적용 시점이 다름
- Filter → Interceptor → AOP
2) 적용 방식이 다름
- Filter: web.xml
- Interceptor: servlet-context.xml
3) 실행 위치가 다름
- Filter: WAS 웹 컨텍스트에서 실행
- Interceptor : 스프링 컨텍스트에서 실행
- AOP: 메소드 앞에 Proxy 패턴의 형태로 실행
4. 세 가지의 사용에 대한 결론
*Filter
-전체적인 Request단에서 어떤 처리가 필요할 때
-인증, 이미지 변환, 데이터 압축, 암호화 필터, 토크 나이징 필터, XML 콘텐츠를 변형하는 XSLT 필터,
URL 및 기타 정보를 캐시 하는 필터
-문자 인코딩 등
*Interceptor
-세션 및 쿠키 체크하는 http 프로토콜 단위로 처리해야 하는 업무가 있을 때
-로그인 세션 체크 등
*AOP
-비즈니스 단에서 세밀하게 조정하고 싶을 때
-로깅, 트랜잭션, 에러 처리 등
스프링 부트와 스프링의 차이
가장 큰 차이점은 Auto Configuration의 차이
- Embed Tomcat을 사용하기 때문에, (Spring Boot 내부에 Tomcat이 포함되어있다.) 따로 Tomcat을 설치하거나 매번 버전을 관리해 주어야 하는 수고로움을 덜어준다.
- starter을 통한 dependency 자동화 :
아마 Spring 유저들이 가장 열광한 기능이 아닐까 싶다. 과거 Spring framework에서는 각각의 dependency들의 호환되는 버전을 일일이 맞추어 주어야 했고, 때문에 하나의 버전을 올리고자 하면 다른 dependeny에 까지 영향을 미쳐 version관리에 어려움이 많았다. 하지만, 이제 starter가 대부분의 dependency를 관리해주기 때문에 이러한 걱정을 많이 덜게 되었다. - Spring FrameWork의 경우 Configuration 설정(XML)을 할때마다 매우 길고 ,모든 어노테이션 및 빈 등록을 하나하나 설정해 줘야하는데, SpringBoot 는 application.properties나 applcation.yml에 설정하면 끝이난다.
- Spring FrameWork로 개발한 애플리케이션의 경우, War파일을 Web Application Server에 담아 배포했는데, Spring Boot의 경우, Tomcat이나 Jetty같은 내장 WAS를 가지고 있어, JAR파일로 간편하게 배포가 가능
starter란 특정 목적을 달성하기 위한 의존성 그룹이라고 생각하면 이해하기 쉽다. starter는 마치 npm처럼 간편하게 dependency를 제공해주는데, 만약 우리가 JPA가 필요하다면 prom.xml(메이븐)이나 build.gradle(그레이들)에 'spring-boot-starter-data-jpa'만 추가해주면 spring boot가 그에 필요한 라이브러리들을 알아서 받아온다.
Spring MVC
MVC는 Model,View,Controller의 약자로 각 레이어간 기능을 구분하는것에 중점을 둔 디자인 패턴입니다.
- Model
- 데이터 관리 및 비즈니스 로직을 처리하는 부분 ( DAO,DTO,Service등 )
- View
- 비즈니스 로직의 처리 결과를 통해 유저 인터페이스에 표현되는 구간 ( html,JSP,Thymeleaf 등 화면을 구성하기도 하고 , Rest API로 서버가 구현된다면 JSON 응답으로 구성되기도 한다. )
- Controller
- 사용자의 요청을 처리하고 Model과 View를 중개하는 역할을 한다. Model과 View는 서로 연결되어 있지 않기 때문에 Controller가 사이에서 통신매체가 되어 줍니다.
MVC의 작동 원리
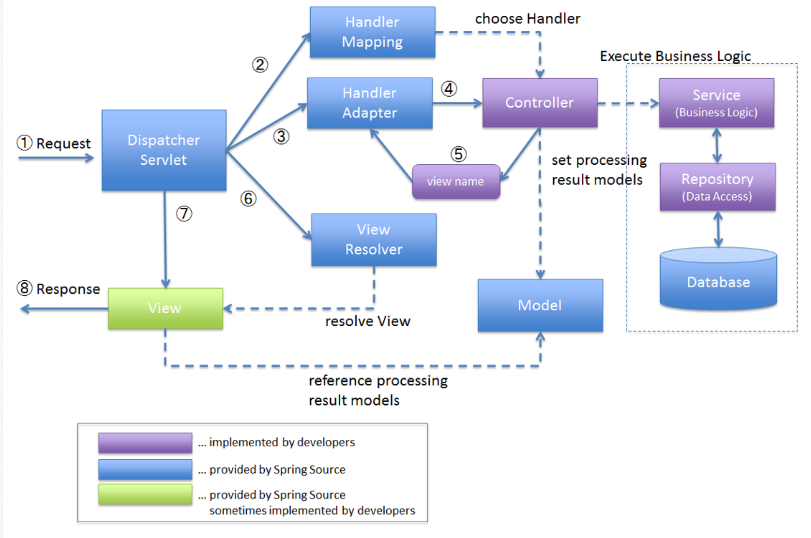
- 클라이언트의 요청을 DispatcherServlet에서 받는다.
- DispatcherServlet은 HandlerMapping을 통해 클라이언트의 요청 URL을 어떤 Controller가 처리할지 결정한다
- HandlerMapping에서 결정된 핸들러 정보로 HandlerAdapter에게 요청의 전달을 맡긴다.
- 핸들러 어댑터는 해당 컨트롤러에 요청을 전달한다.
- 컨트롤러는 비즈니스 로직을 처리한 후에 반환할 뷰의 이름을 DispatcherServlet에게 반환한다.
- 디스패처 서블릿은 뷰 리졸버를 통해 반환할 뷰를 찾는다.
- 디스패처 서블릿은 컨트롤러에서 뷰에 전달할 데이터를 추가한다.
- 데이터가 추가된 뷰를 클라이언트에게 반환한다.